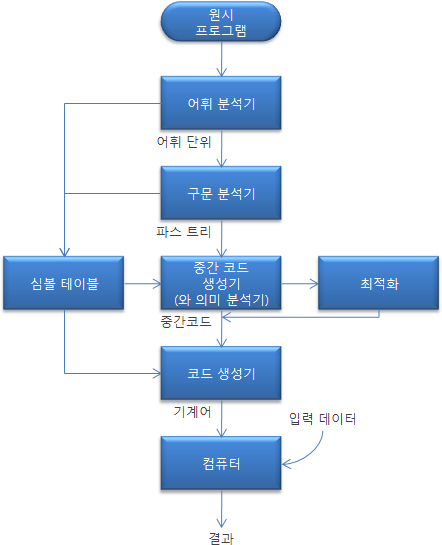
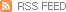
Bubble Sort
정렬이 안 된 오른쪽 리스트를 한번 스캔하면 오른쪽 리스트의 오른쪽 끝에 가장 큰 레코드가 위치하게 되고, 오른쪽 리스트는 추가된 레코드를 포함하여 정렬된 상태가 된다. 이러한 스캔 과정을 정렬이 안된 왼쪽 리스트에서 반복하여 적용하면 정렬이 완료된다.
위 그림은 버블 정렬의 한번의 정렬 과정을 그림으로 표현한 것이다. 먼저 5와 3을 비교하면 5가 더 크므로 서로 교환하고, 다음으로 5와 8을 비교하게 되면 8이 더 크므로 교환 없이 다음 단계로 진행한다. 이러한 과정이 반복되면 8이 가장 리스트의 오른쪽 끝으로 이동하게 된다. 이미 자기 위치에 자리 잡은 8을 제외한 나머지 왼쪽 리스트를 대상으로 이 과정을 반복한다.
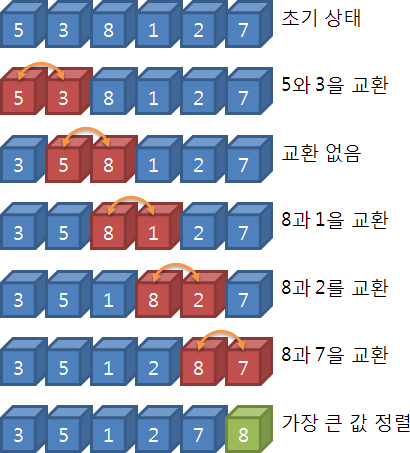
한 번의 반복 과정에 의해 가장 큰 레코드가 리스트의 오른쪽 끝으로 이동하게 된다. 이러한 반복 과정이 왼쪽 리스트가 정렬이 완료될 때까지 수행되며 전체 리스트가 정렬되는 과정은 아래 그림과 같다.
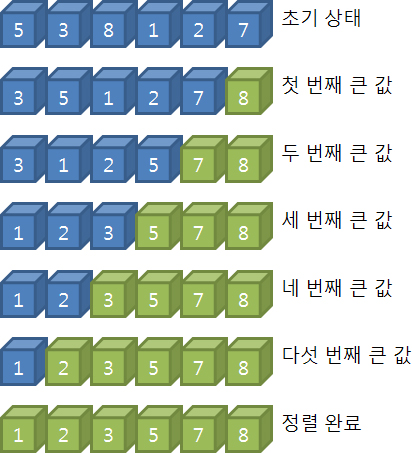

버블 정렬의 알고리즘은 그야 말로 간단하다. 먼저 하나의 스캔은 j = 0 부터 j = i - 1 까지 반복하는 루프로 구성되고 j 번째 요소와 j + 1 번째 요소를 비교하여 크기순으로 되어 있지 않으면 교환한다. i 는 하나의 스캔이 끝날 때마다 1씩 감소한다. 이런 스캔 과정이 n - 1 번 되풀이되면 정렬이 끝나게 된다.
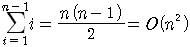
다음은 이동 횟수인데 최악의 이동 횟수는 입력 자료가 역순으로 정렬되어 있는 경우에 발생하고 그 횟수는 비교 연산의 횟수에 3을 곱한 값이다. 왜냐하면 하나의 SWAP함수(또는 매크로)가 3개의 이동을 포함하고 있기 때문이다. 최상의 경우는 입력 자료가 이미 정렬이 되어 있는 경우이다. 이런 경우에는 자료 이동이 한번도 발생하지 않는다. 평균적인 경우에는 자료이동이 0번에서 i번까지 같은 확률로 일어날 것이다. 따라서 이를 기반으로 계산하여 보면
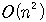 의 알고리즘임을 알 수 있다.
의 알고리즘임을 알 수 있다.
버블 정렬의 가장 큰 문제점은 순서에 맞지 않은 요소를 인접한 요소와 교환한다는 것이다. 하나의 요소가 가장 왼쪽에서 가장 오른쪽으로 이동하기 위해서는 배열에서 모든 다른 요소들과 교환되어야 한다. 특히 특정 요소가 최종 정렬 위치에 이미 있는 경우라도 교환되는 일이 일어난다. 일반적으로 자료의 교환(swap)작업이 자료의 이동(move)작업보다 더 복잡하기 때문에 버블 정렬은 그 단순성에도 불구하고 거의 쓰이지 않고 있다.
- 버블 정렬의 원리
정렬이 안 된 오른쪽 리스트를 한번 스캔하면 오른쪽 리스트의 오른쪽 끝에 가장 큰 레코드가 위치하게 되고, 오른쪽 리스트는 추가된 레코드를 포함하여 정렬된 상태가 된다. 이러한 스캔 과정을 정렬이 안된 왼쪽 리스트에서 반복하여 적용하면 정렬이 완료된다.
위 그림은 버블 정렬의 한번의 정렬 과정을 그림으로 표현한 것이다. 먼저 5와 3을 비교하면 5가 더 크므로 서로 교환하고, 다음으로 5와 8을 비교하게 되면 8이 더 크므로 교환 없이 다음 단계로 진행한다. 이러한 과정이 반복되면 8이 가장 리스트의 오른쪽 끝으로 이동하게 된다. 이미 자기 위치에 자리 잡은 8을 제외한 나머지 왼쪽 리스트를 대상으로 이 과정을 반복한다.
한 번의 반복 과정에 의해 가장 큰 레코드가 리스트의 오른쪽 끝으로 이동하게 된다. 이러한 반복 과정이 왼쪽 리스트가 정렬이 완료될 때까지 수행되며 전체 리스트가 정렬되는 과정은 아래 그림과 같다.
- 버블 정렬의 알고리즘
버블 정렬의 알고리즘은 그야 말로 간단하다. 먼저 하나의 스캔은 j = 0 부터 j = i - 1 까지 반복하는 루프로 구성되고 j 번째 요소와 j + 1 번째 요소를 비교하여 크기순으로 되어 있지 않으면 교환한다. i 는 하나의 스캔이 끝날 때마다 1씩 감소한다. 이런 스캔 과정이 n - 1 번 되풀이되면 정렬이 끝나게 된다.
- 버블 정렬의 C언어 구현
- 버블 정렬의 복잡도 분석
다음은 이동 횟수인데 최악의 이동 횟수는 입력 자료가 역순으로 정렬되어 있는 경우에 발생하고 그 횟수는 비교 연산의 횟수에 3을 곱한 값이다. 왜냐하면 하나의 SWAP함수(또는 매크로)가 3개의 이동을 포함하고 있기 때문이다. 최상의 경우는 입력 자료가 이미 정렬이 되어 있는 경우이다. 이런 경우에는 자료 이동이 한번도 발생하지 않는다. 평균적인 경우에는 자료이동이 0번에서 i번까지 같은 확률로 일어날 것이다. 따라서 이를 기반으로 계산하여 보면
버블 정렬의 가장 큰 문제점은 순서에 맞지 않은 요소를 인접한 요소와 교환한다는 것이다. 하나의 요소가 가장 왼쪽에서 가장 오른쪽으로 이동하기 위해서는 배열에서 모든 다른 요소들과 교환되어야 한다. 특히 특정 요소가 최종 정렬 위치에 이미 있는 경우라도 교환되는 일이 일어난다. 일반적으로 자료의 교환(swap)작업이 자료의 이동(move)작업보다 더 복잡하기 때문에 버블 정렬은 그 단순성에도 불구하고 거의 쓰이지 않고 있다.