1. 컴파일
프로그램 언어는 3개의 일반적인 방법에 의해서 구현될 수 있다. 한 극단적인 방법으로 프로그램은 컴퓨터에서 직접 실행될 수 있는 기계 언어로 번역될 수 있다. 이것을 컴파일러(Compiler) 구현이라 한다. 이 방법은 일단 번역 과정이 완료되면, 매우 빠르게 프로그램을 실행시킬 수 있다는 장점을 갖는다. C, COBOL, Ada와 같은 언어의 대부분 구현은 컴파일러에 의해서 이루어진다.
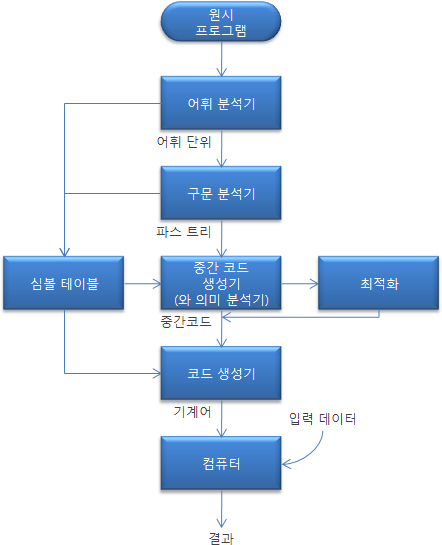
컴파일러가 번역하는 언어를 원시 언어(source language)라고 한다. 컴파일 과정은 여러 단계로 이루어지는데, 이들 중 가장 중요한 단계들이 그림 1에 보여진다.
어휘 분석기(lexical unit)는 원시 프로그램의 문자들을 어휘 단위로 모은다. 프로그램의 어휘 단위는 식별자, 특수어, 연산자, 구분자(punctuation)기호 등이다. 컴파일러에서 주석(comment)은 아무 소용이 없기 때문에, 어휘 분석기는 원시 프로그램에 포함된 주석을 무시한다.
구문 분석기(syntax analyzer)는 어휘 분석기로부터 어휘 단위들을 가져오고, 이들을 사용하여 파스 트리(parse tree)라 불리는 계층적 구조를 생성한다. 이러한 파스 트리는 프로그램의 구문 구조를 표현한다. 대부분의 경우에 파스 트리 구조가 실제적으로 구성되지는 않고, 이 트리를 생성하는 데 필요한 정보가 생성되고 사용된다.
중간 코드 생성기(intermediate code generator)는 다른 언어로 표현된 프로그램을 생성하는데, 이 프로그램은 원시 프로그램과 컴파일러의 최종 출력 프로그램(기계어 프로그램)의 중간 수준에 위치한다. 중간 언어는 때때로 어셈블리어와 매우 유사하며, 어떤 경우에는 실제로 어셈블리어이다. 다른 경우에 중간 코드는 어셈블리어 보다 약간 높은 수준에 있다. 의미 분석기(semantic analyzer)는 중간 코드 생성기의 필수적인 부분이다. 의미 분석기는 구문 분석 시에 탐지하는 것이 불가능한 것은 아닐지라도 타입 오류와 같은 어려운 오류를 검사한다.
프로그램의 크기를 줄이거나 실행 속도를 보다 빠르게(또는 둘 다) 함으로써 프로그램을 향상시키는 최적화(optimization)는 보통 컴파일의 선택 사항이다. 사실, 어떠한 중요한 최적화도 수행할 수 없는 컴파일러도 있다. 이런 유형의 컴파일러는 번역된 프로그램의 실행 속도가 컴파일 속도보다 크게 중요하지 않은 상황에서 사용될 것이다. 이러한 상황의 예는 초급 프로그래머를 위한 컴퓨터 실습실이다. 대부분의 상업과 산업 현장에서는 실행 속도가 컴파일 속도보다 중요하고, 따라서 최적화를 일상적으로 수행하는 것이 보통 바람직하다. 많은 유형의 최적화가 기계 언어에서 수행하는 것이 어렵기 때문에, 대부분의 최적화는 중간 코드에서 이루어진다.
코드 생성기(code generator)는 프로그램의 최적화된 중간 코드를 동등한 기계 언어 프로그램으로 변환한다.
심볼 테이블은 컴파일 과정에서 데이터베이스로서 사용된다. 심볼 테이블의 주요 내용은 프로그램에서 사용자가 정의한 각 이름에 대한 타입과 속성 정보이다. 이러한 정보는 어휘 분석기와 구문 분석기에 의해서 심볼 테이블에 저장되고, 의미 분석기와 코드 생성기에 의해서 사용된다.
위에서 설명하였듯이, 컴파일러가 생성한 기계 언어가 직접 하드웨어에서 실행 될 수 있을지라도, 기계 코드는 거의 항상 다른 코드와 함께 실행되어야 한다. 또한, 대부분의 사용자 프로그램은 운영체제로부터 프로그램을 요구한다. 이러한 프로그램 중에서 가장 일반적인 것은 입력과 출력을 위한 프로그램이다. 컴파일러는 사용자 프로그램에서 요구할 때 필요한 시스템 프로그램에 대한 호출을 생성한다. 컴파일러가 생성한 기계 언어 프로그램이 실행될 수 있기 전에, 요구된 시스템 프로그램이 운영체제로부터 찾아져서 사용자 프로그램에 연결되어야 한다. 링킹 연산(linking operation)은 사용자 프로그램에서 요구한 시스템 프로그램의 호출 위치에 그 시스템 프로그램의 시작 주소를 저장함으로써 사용자 프로그램을 시스템 프로그램에 연결한다. 사용자 코드와 시스템 코드는 함께 적재 모듈(load module), 또는 실행 가능 이미지(executable image) 불린다. 시스템 프로그램들을 수집하고 이들을 사용자 프로그램에 연결하는 과정을 링킹(linking)과 적재(loading)라고 부르며, 또는 때때로 단지 링킹이라고 부른다. 이 과정은 링커(linker)라고 부르는 시스템 프로그램에 의해서 수행된다.
시스템 프로그램 외에도 사용자 프로그램은 보통 라이브러리에 존재하는 이미 컴파일된 다른 사용자 프로그램에 링킹되어야 한다. 따라서 링커는 주어진 프로그램을 시스템 프로그램에 링킹할 뿐만 아니라, 다른 사용자 프로그램에도 링킹할 수 있다.
폰 노이만 구조 컴퓨터에서 기계 코드 프로그램의 실행은 인출-실행 사이클(fetch-execution cycle)이라 불리는 과정으로 이루어진다. 프로그램은 기억장소에 저장되어 있지만 CPU에서 실행된다. 실행될 각 명령어는 기억장소에서 프로세서로 옮겨져야 한다. 다음에 실행할 명령어의 주소는 프로그램 계수기(program counter)라 불리는 레지스터에 유지되어 있다. 인출-실행 사이클은 다음 알고리즘으로 간단히 기술될 수 있다.
프로그램 계수기를 초기화한다.
repeat forever
프로그램 계수기가 가리키는 명령어를 인출한다.
다음 명령어를 가리키기 위해 프로그램 계수기를 증가시킨다.
명령어를 해석한다.
명령어를 실행한다.
end repeat
위 과정의 명령어 해석 단계에서는 명령어에 어떤 연산이 명세되어 있는지를 결정하기 위해서 명령어를 조사한다. 실제 컴퓨터에서 stop 명령어가 거의 실행되지 않을지라도, 프로그램 실행은 stop 명령어를 만나면 종료된다. 제어는 사용자 프로그램을 실행시키기 위해서 운영체제로부터 그 사용자 프로그램에 전달되고, 사용자 프로그램의 실행이 완료되면 다시 운영체제로 전달된다. 주어진 시간에 한 개 이상의 사용자 프로그램이 기억장소에 존재할 수 있는 컴퓨터 시스템에서 이러한 과정은 훨씬 더 복잡해진다.
명령어는 보통 실행을 위해서 프로세서에 옮기는 데 걸리는 시간보다 더 빠르게 실행될 수 있기 때문에 컴퓨터의 기억장소와 프로세서를 연결하는 속도는 보통 컴퓨터의 속도를 결정한다. 이러한 연결을 폰 노이만 병목(von Neumann bottleneck)이라 한다. 이것은 폰 노이만 구조 컴퓨터의 속도를 제한하는 주요 요소이다. 폰 노이만 병목은 병렬 컴퓨터의 연구와 개발을 위한 주요 동기중의 하나였다.
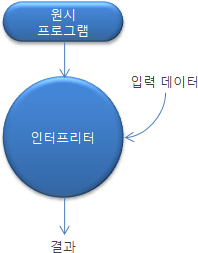
2. 순수 해석 순수 해석(pure interpretation)은 구현 방법의 스텍트럼 상에서(컴파일과는 다른) 정반대의 위치에 속한다. 이 방법을 사용하여 프로그램은 어떠한 번역 과정 없이 인터프리터(interpreter)라 불리는 다른 프로그램에 의해서 해석(interpret)될 수 있다. 인터프리터 프로그램은 인출-실행 사이클이 기계 명령어가 아닌 고급 언어 프로그램을 다루는 기계의 소프트웨어 모의실험(simulation)으로서 동작한다. 이러한 소프트웨어 모의실험은 확실히 그 언어에 대한 가상 기계를 제공한다.
순수 해석은 많은 원시 프로그램 수준의 디버깅 연산을 쉽게 구현할 수 있는 장점을 가진다. 이것은 모든 실행 시간 오류 메시지가 원시 수준 단위를 참조할 수 있기 때문이다. 예를 들면, 배열 인덱스가 범위를 벗어낫다는 것이 발견되면, 어류메시지는 원시 프로그램의 행과 배열 이름을 쉽게 나타낼 수 있다. 반면에, 이러한 방법은 실행 시간이 컴파일된 시스템의 경우보다 10배 내지 100배 정도 느리다는 심각한 단점을 갖는다. 이렇게 실행 속도가 느린 주요 요인은 기계 언어 명령어보다 훨씬 더 복잡한 고급 언어 문장을 해석한다는 데 있다(동일한 의미를 갖는 기계 코드의 명령어보다 문장수가 더 적을지라도). 더욱이, 문장이 반복 실행되는 회수와는 무관하게, 그 문장은 매번 해석되어야 한다. 그러므로 프로세서와 기억장소간의 연결보다는 문장 해석이 순수 인터프리터의 병목이다.
순수 인터프리터의 다른 단점은 보통 더 많은 기억공간을 요구한다는 데 있다. 원시 프로그램 외에도 심볼 테이블이 해석하는 동안에 존재해야 한다. 더욱이, 원시 프로그램은 최소의 크기로 제공된 형태보다는 접근과 수정이 용이하도록 설계된 형태로 저장될 수 있다.
1960년대의 단순한 초기 언어(APL, SNOBOL, LISP)들이 순수 해석으로 구현되었지만, 1980년대에는 이 방법이 고급 언어에 대해서 거의 사용되지 않았다. 그러나 최근에 순수 해석이 현재 널리 사용되고 있는 JavaScript와 PHP와 같은 웹 스크립트 언어에 의해서 다시 사용되고 있다.
순수 인터프리터의 과정이 그림 2에서 보여진다.
3. 혼합형 구현 시스템
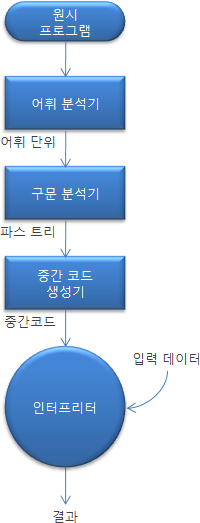
어떤 언어 구현 시스템은 컴파일러와 순수 인터프리터의 절충 형태이다. 즉, 이 시스템은 고급 언어 프로그램을 쉽게 해석하기 위해 설계된 중간 언어로 변역한다. 이 방법은 원시 언어 문장이 단지 한번만 해석되기 때문에 순수 해석보다 더 빠르다. 이러한 구현을 혼합형 구현 시스템(hybrid implementation system)이라 한다.
혼합형 구현 시스템에서 사용된 처리 과정이 그림 3에 보여진다. 중간 언어 코드를 기계 코드로 번역하는 대신에 혼합형 구현 시스템은 그 중간 코드를 단순히 해석한다.
Perl은 혼합형 시스템으로 구현되었다. 이 언어는 순수 해석 언어 sh와 awk로부터 발전되었으나, 해석 단계 전에 오류를 탐지하고 인터프리터를 단순하게 하기위해 부분적으로 번역된다.
Java의 초기 구현은 모두 혼합 형태였다. 바이트 코드라 불리는 그 중간 코드 형태는 바이트 코드 인터프리터와 관련된 실행 시간 시스템을 가지고 있는 기계에 이식성을 제공한다. 이러한 바이트 코드 인터프리터와 관련된 실행 시간 시스템을 함께 Java 가상 기계(Java Virtual Machine)라 한다. 현재는 더 빠른실행을 위해서 Java 바이트 코드를 기계 코드로 번역하는 시스템이 존재한다. 그러나 Java애플릿(applet)은 항상 웹서버로부터 바이트 코드의 형태로 다운로드(download) 된다.
때때로 구현자는 한 언어에 대해서 컴파일 구현과 인터프리터 구현 모두를 제공할 수 있다. 이러한 경우에 인터프리터는 프로그램을 개발하고 디버깅하는데 사용된다. 다음에, (상대적으로) 버그가 없는 상태에 이르면, 프로그램은 실행 속도를 향상시키기 위해서 컴파일 된다.